Cómo puedo almacenar archivos en Kubernetes? CubeFS es una excelente opción

¿Qué es CubeFS?
CubeFS es un producto de almacenamiento cloud-native, siendo uno de los proyectos en grado "Incubator" de la CNCF ( Cloud Native Computing Foundation). Es compatible con varios protocolos de acceso a datos, como S3, POSIX y HDFS, y admite dos motores de almacenamiento: múltiples réplicas y erasure code. Brinda a los usuarios múltiples funciones, como multiusuario, implementación multi-AZ y replicación entre regiones, y se usa ampliamente en escenarios como big data, IA, plataformas de contenedores, bases de datos, almacenamiento de middleware y separación informática, uso compartido de datos y protección de Datos.
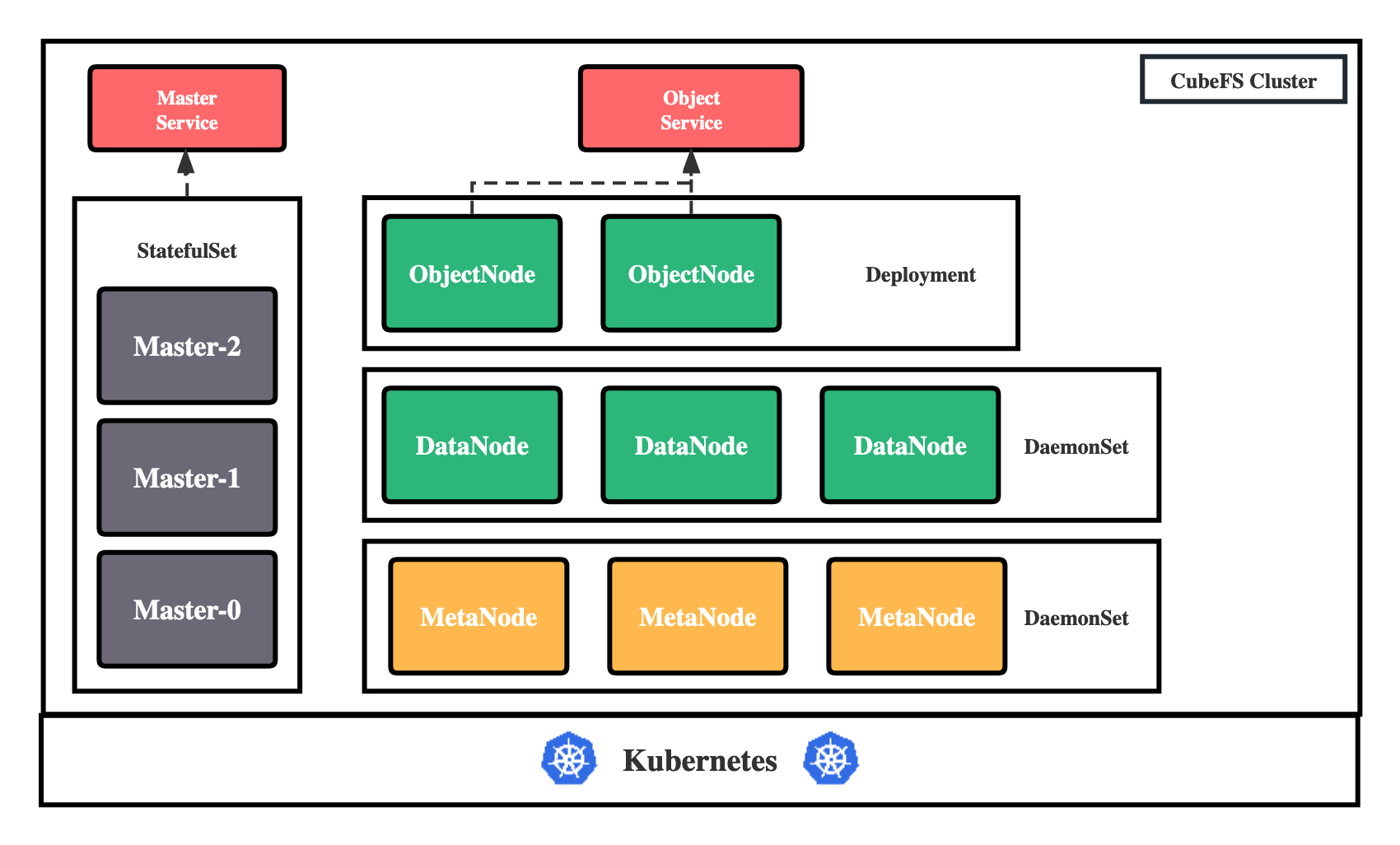

¿Por qué CubeFS?
Multiprotocolo
Compatible con diversos protocolos de acceso como S3, POSIX y HDFS, y el acceso entre protocolos es interoperable.
- Compatible con POSIX: Compatible con la interfaz POSIX, lo que hace que el desarrollo de aplicaciones sea extremadamente simple para aplicaciones de capa superior, tan conveniente como usar un sistema de archivos local. Además, CubeFS relajó los requisitos de coherencia de la semántica POSIX durante la implementación para equilibrar el rendimiento de las operaciones de archivos y metadatos.
- Compatible con S3: compatible con el protocolo de almacenamiento de objetos de AWS S3, los usuarios pueden usar el SDK nativo de Amazon S3 para administrar recursos en CubeFS.
- Compatible con HDFS: Compatible con el protocolo de interfaz Hadoop FileSystem, los usuarios pueden usar CubeFS para reemplazar el sistema de archivos Hadoop (HDFS) sin afectar el negocio de capa superior.
Multimotor
Al admitir dos motores: múltiples réplicas y codificación de borrado, los usuarios pueden elegir de manera flexible de acuerdo con sus escenarios comerciales.
- Motor de almacenamiento de múltiples réplicas: los datos entre copias están en una relación de espejo y la coherencia de los datos entre copias se garantiza a través de un protocolo de replicación muy coherente. Los usuarios pueden configurar de manera flexible diferentes números de copias según los escenarios de su aplicación.
- Motor de almacenamiento de codificación de borrado:El motor de codificación de borrado tiene las características de alta confiabilidad, alta disponibilidad, bajo costo y admite escala ultra grande (EB). De acuerdo con los diferentes modelos AZ, los modos de codificación de borrado se pueden seleccionar de manera flexible.
Multiusuario
Apoyar la administración de múltiples inquilinos y proporcionar políticas detalladas de aislamiento de inquilinos.
Altamente escalable
Puede construir fácilmente servicios de almacenamiento distribuido con escala de nivel PB o EB, y cada módulo se puede escalar horizontalmente.
Alto rendimiento
CubeFS admite el almacenamiento en caché de varios niveles para optimizar el acceso a archivos pequeños y admite múltiples protocolos de replicación de alto rendimiento.
- Gestión de metadatos: el clúster de metadatos usa almacenamiento de metadatos en memoria y utiliza dos árboles B (inodeBTree y dentryBTree) para administrar índices y mejorar el rendimiento del acceso a los metadatos.
- Protocolo de replicación de consistencia sólida:CubeFS adopta diferentes protocolos de replicación de acuerdo con el modo de escritura del archivo para garantizar la consistencia de los datos entre las réplicas. Si el archivo se escribe secuencialmente, se utiliza el protocolo de replicación principal-respaldo para optimizar el rendimiento de E/S. Si el archivo se escribe aleatoriamente para sobrescribir el contenido del archivo existente, se utiliza un protocolo de replicación basado en Multi-Raft para garantizar una gran coherencia de los datos.
- Almacenamiento en caché de niveles múltiples: el volumen de codificación de borrado admite la capacidad de aceleración de almacenamiento en caché de niveles múltiples para proporcionar un mayor rendimiento de acceso a datos para datos calientes:
- Caché local: el componente BlockCache se puede implementar en la máquina cliente como un caché local utilizando el disco local. Puede leer directamente la memoria caché local sin pasar por la red, pero la capacidad está limitada por el disco local.
- Caché global: una caché global distribuida creada con el componente de réplica DataNode. Por ejemplo, un DataNode con un disco SSD implementado en el mismo centro de datos que el cliente se puede usar como caché global. En comparación con el caché local, debe pasar por la red, pero tiene una mayor capacidad y se puede escalar dinámicamente, y se puede ajustar la cantidad de réplicas.
Cloud Native
Basado en el standard CSI (Container Storage Interface) , CubeFS se integra y despliega fácilmente en Kubernetes.
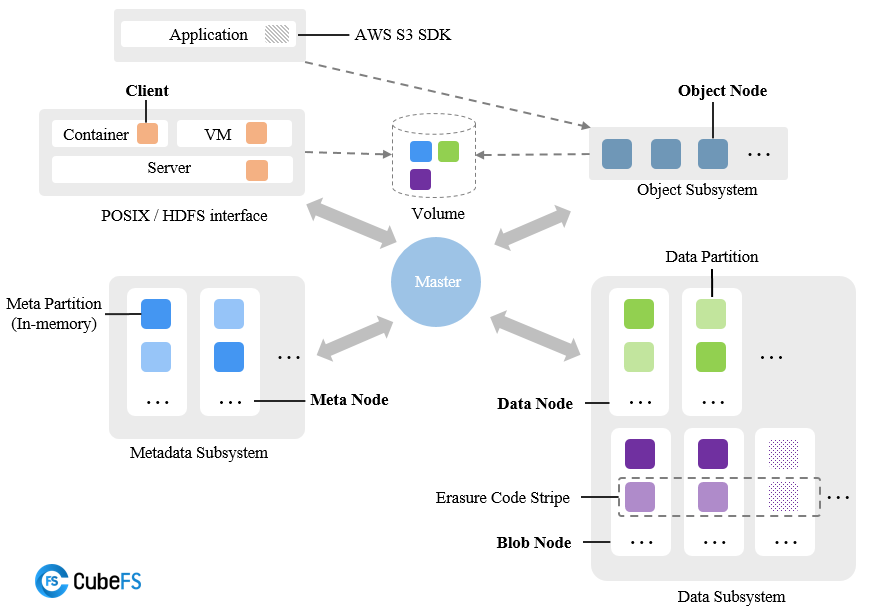
Casos y escenarios de uso
Como plataforma de almacenamiento distribuido nativa de la nube, CubeFS proporciona múltiples protocolos de acceso, por lo que puedes utilizarlo en distintas situaciones, enumeremos:
Análisis de grandes datos
Compatible con el protocolo HDFS, CubeFS proporciona una base de almacenamiento unificado para el ecosistema Hadoop (como Spark y Hive), proporcionando espacio de almacenamiento ilimitado y capacidades de almacenamiento de datos de gran ancho de banda para motores informáticos.
Deep Learning/Machine Learning
Como sistema de archivos paralelos distribuidos, CubeFS es compatible con el entrenamiento de IA, el almacenamiento y la distribución de modelos, la aceleración de E/S y otros requisitos.
Almacenamiento compartido entre contenedores
El clúster de contenedores puede almacenar los archivos de configuración o los datos de carga de inicialización de las imágenes de contenedores en CubeFS, y leerlos en tiempo real cuando se cargan contenedores por lotes. Múltiples PODs pueden compartir datos persistentes a través de CubeFS, y se puede realizar una rápida conmutación por error en caso de fallo del POD.
Bases de datos y middleware
Proporciona servicios de disco en nube de alta concurrencia y baja latencia para aplicaciones de bases de datos como MySQL, ElasticSearch y ClickHouse, consiguiendo una separación completa entre almacenamiento e informática.
Servicios en línea
Proporciona servicios de almacenamiento de objetos de alta fiabilidad y bajo coste para negocios en línea (como publicidad, secuencias de clics y búsquedas) o contenidos gráficos, de texto, audio y vídeo de usuarios finales.
De NAS (Network Attached Storage) a la nube
Sustituye el almacenamiento local tradicional y el NAS sin conexión y facilita estrategias en cloud adoption.
Fuente:
https://cubefs.io/docs/master/overview/introduction.html#database-middleware

Más contenido:

Kubernetes será "el sistema operativo de la IA": La apuesta de Google con GKE Agent Sandbox e Hypercluster
Ya sea que necesites gestionar un millón de H100s o solo quieras asegurarte de que tu agente de IA no tire un rm -rf / en producción, las actualizaciones del Next '26 de GKE sugieren que el futuro de la IA es, inevitablemente, un archivo YAML.
Leer más →

How the Linux kernel copyfail vulnerability impacts kubernetes: What you need to know and what you can do
copy fail in kubernetes: when your pod escapes to the host with four bytes if you thought containers were a security boundary, cve-2026-31431 ("copy fail") has some unfortunate news for you. discovered by xint, this linux kernel vulnerability lets an unprivileged local user overwrite four controlled bytes in
