Como posso armazenar arquivos no Kubernetes? CubeFS é uma excelente opção

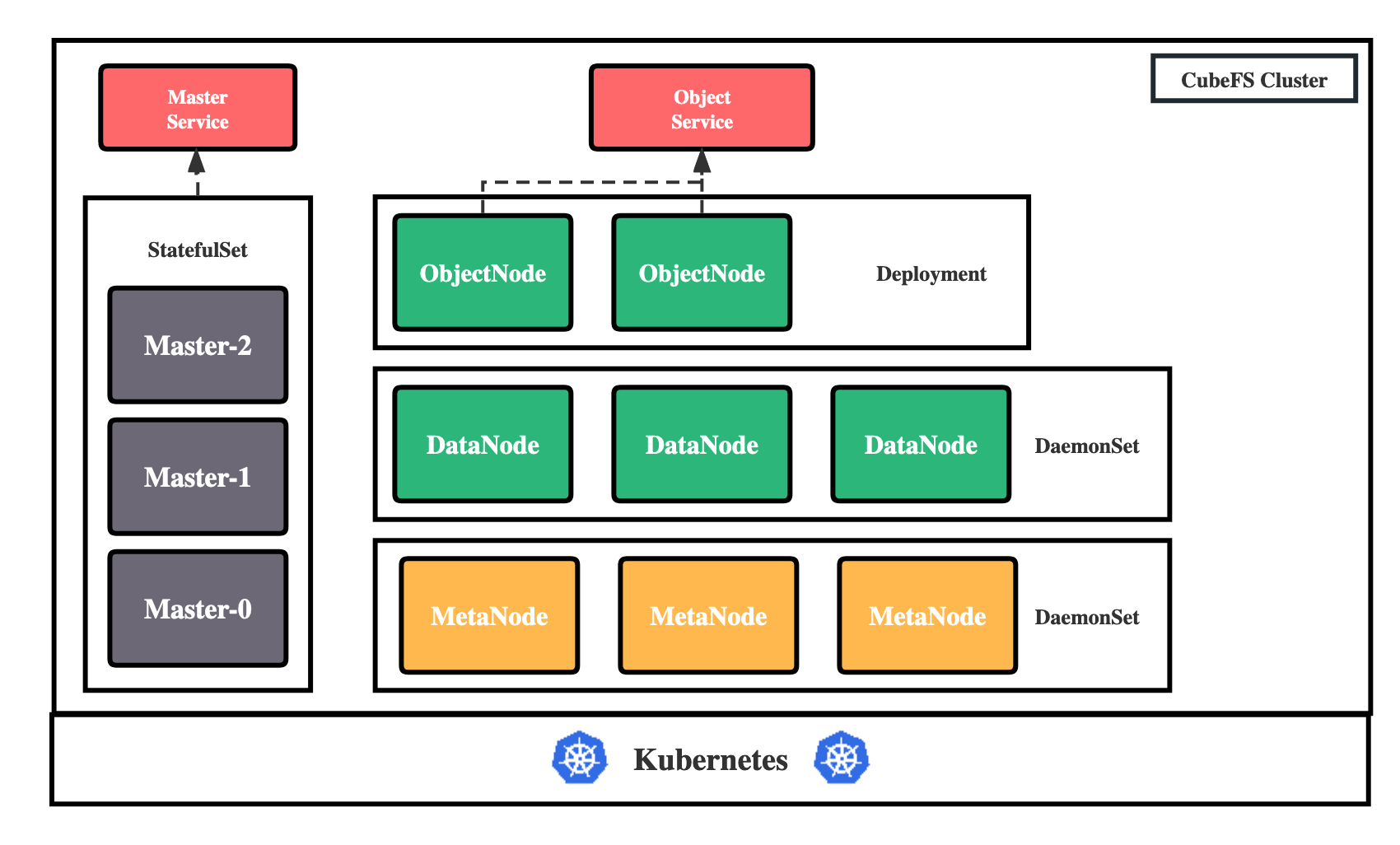

O que é CubeFS?
CubeFS é um produto de armazenamento nativo em nuvem, sendo um dos projetos de grau "Incubadora" da CNCF ( Cloud Native Computing Foundation ). Ele suporta vários protocolos de acesso a dados, como S3, POSIX e HDFS, e suporta dois mecanismos de armazenamento : multi-réplica e código de eliminação . Ele fornece aos usuários múltiplas funções, como multilocação, implantação multi-AZ e replicação entre regiões, e é amplamente utilizado em cenários como big data, IA, plataformas de contêiner, bancos de dados, armazenamento de middleware e separação de computação, compartilhamento de dados e Proteção de dados.
Por que CubeFS?
Multiprotocolo
Suporta vários protocolos de acesso como S3, POSIX e HDFS, e o acesso entre protocolos é interoperável.
- Compatível com POSIX : Compatível com a interface POSIX, tornando o desenvolvimento de aplicativos extremamente simples para aplicativos de camada superior, tão conveniente quanto usar um sistema de arquivos local. Além disso, o CubeFS relaxou os requisitos de consistência da semântica POSIX durante a implementação para equilibrar o desempenho das operações de arquivos e metadados.
- Compatível com S3 – Com suporte ao protocolo de armazenamento de objetos AWS S3, os usuários podem usar o SDK nativo do Amazon S3 para gerenciar recursos no CubeFS.
- Compatível com HDFS : Compatível com o protocolo de interface Hadoop FileSystem, os usuários podem usar CubeFS para substituir o sistema de arquivos Hadoop (HDFS) sem afetar os negócios da camada superior.
Multimotor
Ao oferecer suporte a dois mecanismos: multi-réplica e codificação de eliminação, os usuários podem escolher com flexibilidade de acordo com seus cenários de negócios.
- Mecanismo de armazenamento multi-réplica : os dados entre as cópias estão em um relacionamento de espelho e a consistência dos dados entre as cópias é garantida por meio de um protocolo de replicação altamente consistente. Os usuários podem configurar com flexibilidade diferentes números de cópias de acordo com os cenários de sua aplicação.
- Mecanismo de armazenamento de codificação de eliminação : O mecanismo de codificação de eliminação tem as características de alta confiabilidade, alta disponibilidade, baixo custo e suporta escala ultragrande (EB). De acordo com os diferentes modelos AZ, os modos de codificação de eliminação podem ser selecionados de forma flexível.
Multi usuário
Apoie o gerenciamento de vários locatários e forneça políticas detalhadas de isolamento de locatários.
Altamente escalável
Você pode criar facilmente serviços de armazenamento distribuído com escala de nível PB ou EB, e cada módulo pode ser escalado horizontalmente.
Alto rendimento
CubeFS suporta cache multinível para otimizar o acesso a arquivos pequenos e oferece suporte a vários protocolos de replicação de alto desempenho.
- Gerenciamento de metadados - O cluster de metadados usa armazenamento de metadados na memória e duas árvores B (inodeBTree e dentryBTree) para gerenciar índices e melhorar o desempenho de acesso aos metadados.
- Protocolo de replicação de consistência forte : CubeFS adota diferentes protocolos de replicação de acordo com o modo de gravação do arquivo para garantir a consistência dos dados entre as réplicas. Se o arquivo for gravado sequencialmente, o protocolo de replicação de backup primário será usado para otimizar o desempenho de E/S. Se o arquivo for gravado aleatoriamente para substituir o conteúdo do arquivo existente, um protocolo de replicação baseado em Multi-Raft será usado para garantir alta consistência de dados.
- Cache multinível – O volume de codificação Erasure suporta capacidade de aceleração de cache multinível para fornecer maior desempenho de acesso a dados para dados importantes:
- Cache Local: O componente BlockCache pode ser implantado na máquina cliente como um cache local usando o disco local. Ele pode ler diretamente o cache local sem passar pela rede, mas a capacidade é limitada pelo disco local.
- Cache Global: Um cache global distribuído criado com o componente de replicação DataNode. Por exemplo, um DataNode com SSD implantado no mesmo data center do cliente pode ser usado como cache global. Comparado com o cache local, ele precisa passar pela rede, mas tem maior capacidade e pode ser dimensionado dinamicamente, e o número de réplicas pode ser ajustado.
Nativo da nuvem
Baseado no padrão CSI (Container Storage Interface ), o CubeFS é facilmente integrado e implantado no Kubernetes.

Casos de uso e cenários
Por ser uma plataforma de armazenamento distribuído nativa em nuvem, o CubeFS disponibiliza vários protocolos de acesso, para que você possa utilizá-lo em diversas situações, vamos listar:
Análise de big data
Compatível com o protocolo HDFS, o CubeFS fornece uma base de armazenamento unificada para o ecossistema Hadoop (como Spark e Hive), fornecendo espaço de armazenamento ilimitado e recursos de armazenamento de dados de alta largura de banda para mecanismos de computação.
Aprendizado profundo/aprendizado de máquina
Como um sistema de arquivos paralelo distribuído, o CubeFS suporta treinamento de IA, armazenamento e distribuição de modelos, aceleração de E/S e outros requisitos.
Armazenamento compartilhado entre contêineres
O cluster de contêiner pode armazenar os arquivos de configuração ou dados de carregamento de inicialização de imagens de contêiner no CubeFS e lê-los em tempo real ao carregar contêineres em lote. Vários PODs podem compartilhar dados persistentes por meio do CubeFS e um failover rápido pode ser executado em caso de falha do POD.
Bancos de dados e middleware
Fornece serviços de disco em nuvem de alta simultaneidade e baixa latência para aplicativos de banco de dados como MySQL, ElasticSearch e ClickHouse, alcançando separação completa entre armazenamento e computação.
Serviços online
Fornece serviços de armazenamento de objetos de alta confiabilidade e baixo custo para empresas on-line (como publicidade, fluxos de cliques e pesquisas) ou conteúdo gráfico, de texto, áudio e vídeo do usuário final.
Do NAS (Network Attached Storage) à nuvem
Ele substitui o armazenamento local tradicional e o NAS offline e facilita estratégias de adoção da nuvem.
Fonte:

Nicolás Georger
Cybernetics, Linux, Kubernetes enthusiast. SRE/DevOps practitioner. Self educated IT professional. Founder of @sredevopsorg, currently exploring AI, LLM, ML.
- Login with Linkedin
- Login with Github